Written by Rodrigo Sanabria, Director Partner Success, Latin America
On a prior post by Carlos del Carpio (“The Economics of Credit Scoring”), we discussed the business considerations to assess the merit of a risk model. In this post, I will address how a good origination model impacts the bottom line of a company’s P&L.
These principles may be adapted to look into other types of models used at later stages of a loan life, but on this post we will only address loan origination.
From a business point of view, an origination model is a tool that helps us aim at the “sweet spot”: where we maximize profits. A simple way to think about it is as a trade-off between the cost of acquisition (per loan disbursed) and cost of defaults (provisions, write-offs): The higher the approval rate, the lower the cost of acquisition, but the number of defaults go up.
How do we go about finding the sweet spot? I’ll try to explain it below.

Figure 1
A good model has a good Gini. A “USEFUL” model creates a steep probability of default (also known as PD) curve – we usually refer to it as a “risk split”.
Figure 1 shows the performance of a model based on psychometric information used by an MFI. The Gini (not shown in the graphic) is pretty good (0.28). The risk split is great: the people in the lower 20% of the score ranking are about 9 times more likely to default than those in the top 20%.
Knowing the probability of default for a given group, we may set a credit policy. Basically, we need to answer: “what would the default look like given an acceptance rate?”
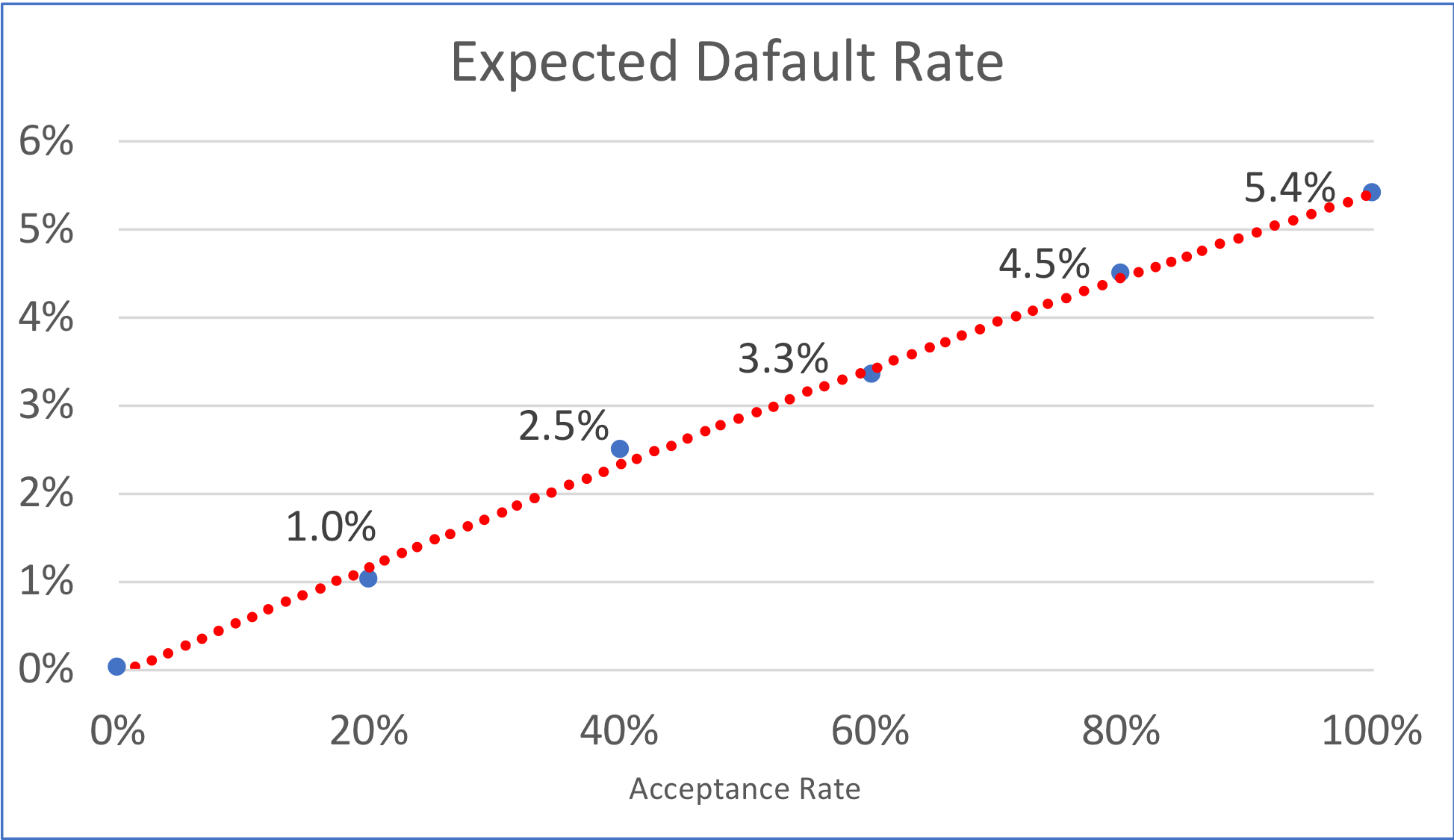
Figure 2
We have re-plotted the same data in Figure 2, but now we express the probability of default in accumulated terms. Basically, the graph shows that if we were to accept 80% of this population sample, we would have a 4.5% PD, but if we were to accept 40%, the PD would go down 2 points to 2.5%.
Now, from a business point of view, we still do not have enough information to decide. Do we?
Where would the profit be maximized?
The total cost of customer acquisition is mainly fixed. Whatever we spend on marketing and sales to attract this population, will not change if we reject more or fewer applicants. So, the cost per loan disbursed would grow as we reduce the acceptance rate.
Of course, the higher the acceptance rate, the larger the portfolio, and the more interest revenue we get. BUT, the higher the provisions and write-offs. The combination of these 2 variables (cost of acquisition and net interest income) produces an inverted U-shaped curve that uncovers the “sweet spot”

Figure 3
The current credit policy is yielding a profit at 100% acceptance rate (see Figure 3) because the sample being analyzed corresponds to all the customers that were accepted (i.e. we have repayment data about them). So, the portfolio is profitable.
But the sweet spot seems to be shy of 60% acceptance rate. If this FI were to cut down its approval rate to that level, profits would increase by about a third, and its return on portfolio value would almost double. Of course, there are other considerations around market share and capital adequacy that may play a role in such a strategic decision, but the opportunity is clearly uncovered by the model.
In my experience, the sweet spot usually lies within 30%-70% acceptance rates, driven by marketing expenditures, interest rates, cost of capital, sales channels, and regulation.
What if the shape of the curve shows a continuous positive growth? The sweet spot is at a 100% acceptance rate! – have we reached risk karma? – Most likely, the answer is no (but almost!).
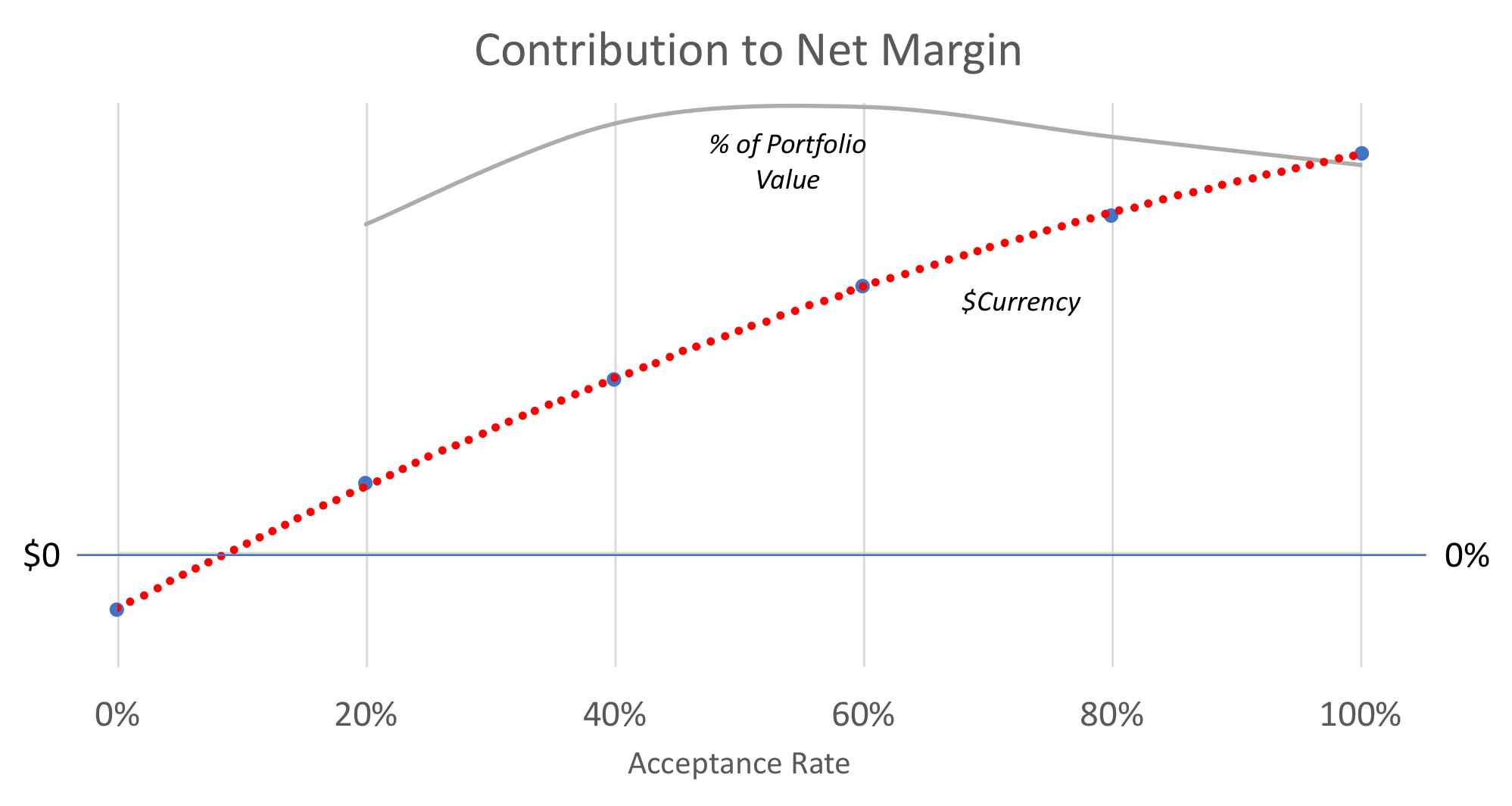
Figure 4
Most likely, we are leaving money on the table. Some business rule may be filtering people before they are scored. I have experienced this situation while working with lenders. For example, a traditional bank was filtering out all SMEs that had been operating for less than X years. This bias in the population was creating a great portfolio from a PD point of view, but there was clearly an opportunity to include younger businesses. As you can see in Figure 4, the maximum return on the portfolio was achieved at 60% approval rate, but they could increase profits by approving beyond the current acceptance rate. Depending on their cost of capital, it may be a good idea to expand the portfolio by approving more people.
In summary, think of your origination model as a business tool. Don’t stop at looking at Gini to assess a model’s merit. Understand how your profitability would be impacted by changes in your acceptance rate. If the PD curve is steep enough, you may capture quite a lot of value by applying the model to either reduce or increase your acceptance rate.





